
Stel je voor: je exporteert een enorme chatgeschiedenis van vijf jaar met je beste vriend, in de verwachting dat een AI-tool deze ruwe tekstbestanden direct omzet in een betekenisvol verhaal. Je plakt de logbestanden in een standaard tekstveld, om vervolgens een generieke samenvatting vol hallucinaties te ontvangen die alle inside jokes en de chronologische context volledig mist. Deze mijlpaalanalyse vergelijkt de prestaties van algemene modellen met gespecialiseerde samenvattings-apps en onthult dat gebruikers handmatige prompt-engineering massaal de rug toekeren ten gunste van doelgerichte, geïntegreerde architecturen. Nu we de grens van 100.000 verwerkte chatexports zijn gepasseerd, bevestigt de data een structurele verschuiving: mensen willen systemen die hun persoonlijke geschiedenis begrijpen zonder dat ze zelf als 'prompt-engineer' hoeven op te treden.
Het einde van de chatbot-hypefase
De afgelopen jaren bestond het standaardgebruikersgedrag voor tekstanalyse uit het kopiëren en plakken van data in de interface die op dat moment voorhanden was. Of ze nu chatgpt typten, gemini uitprobeerden of experimenteerden met nieuwere modellen zoals deepseek en grok ai; de verwachting was dat een voldoende geavanceerd model elke rommelige brij aan data wel kon ontcijferen. De retentiedata uit de praktijk vertelt echter een ander verhaal.
Volgens het Mobil Uygulama Trendleri 2026-rapport van Adjust is de initiële "AI-hype" officieel voorbij. Het rapport benadrukt dat de wereldwijde uitgaven aan consumenten-apps in 2025 met 10,6% zijn gestegen naar 167 miljard dollar, waarbij het totaal aantal app-sessies met 7% toenam. Cruciaal is dat de onderzoekers opmerkten dat groei in 2026 sterk afhangt van operationele discipline — specifiek de end-to-end integratie van AI voor segmentatie, inzichten en optimalisatie, in plaats van te vertrouwen op gefragmenteerde, losstaande tools. Gebruikers willen geen losse tool meer waarbij ze zelf het zware werk moeten doen; ze verwachten dat de applicatie de volledige workflow zelfstandig beheert.
In mijn ervaring met het ontwerpen van locatiegebaseerde diensten en tracking-apps voor families, heb ik exact dezelfde gedragsverandering gezien. Wanneer gebruikers omgaan met diep persoonlijke gegevens — of het nu gaat om locatiecoördinaten of privéberichten — geven ze de voorkeur aan gesloten, gespecialiseerde omgevingen boven het plakken van hun leven in een openbare webinterface. Ze willen een op maat gemaakte ervaring die de structuur van hun data respecteert.
Twee benaderingen vergeleken: Doe-het-zelf vs. Doelgericht
Om te begrijpen waarom deze verschuiving plaatsvindt, moeten we de handmatige aanpak van een standaard ai chatbot vergelijken met een toegewijde workflow zoals Wrapped AI Chat Analysis Recap. Als je een gestructureerd verhaal wilt van je relatiedynamiek, is de verwerkingsengine van Wrapped AI specifiek ontworpen voor dat resultaat, waardoor veelvoorkomende fouten van algemene modellen worden omzeild.
Benadering A: De algemene AI-prompt
Wanneer een gebruiker probeert een groot bestand te verwerken via een standaard gpt chat of vergelijkbare webinterface, stuit hij onmiddellijk op frictie. Chatlogs geëxporteerd van platforms zoals whatsapp web of whatsapp messenger bevatten tijdstempels, systeemberichten en media-placeholders die algemene taalmodellen in de war brengen.
- Token-limieten: De meeste standaardmodellen hebben een limiet voor de hoeveelheid tekst die je kunt invoeren. Een jaar aan dagelijkse berichten overschrijdt deze limieten ruimschoots, waardoor de gebruiker zijn tekst handmatig in stukken moet hakken.
- Context-fragmentatie: Omdat de tekst wordt opgesplitst, verliest het model de overkoepelende tijdlijn. Het kan denken dat een ruzie die in maart is opgelost, in december nog steeds gaande is.
- Hallucinaties: Geconfronteerd met ongestructureerde data verzinnen algemene tools regelmatig context of voegen ze twee verschillende personen samen tot één personage.
We zien dat gebruikers constant zoeken naar omwegen door zoekopdrachten in te voeren als wchat gpt, chat gp t, of zelfs spelfouten zoals char gbt en gbt char, in de hoop een specifiek prompt-sjabloon te vinden dat hun output repareert. Maar de fout ligt niet bij de prompt; het ligt bij de architectuur.
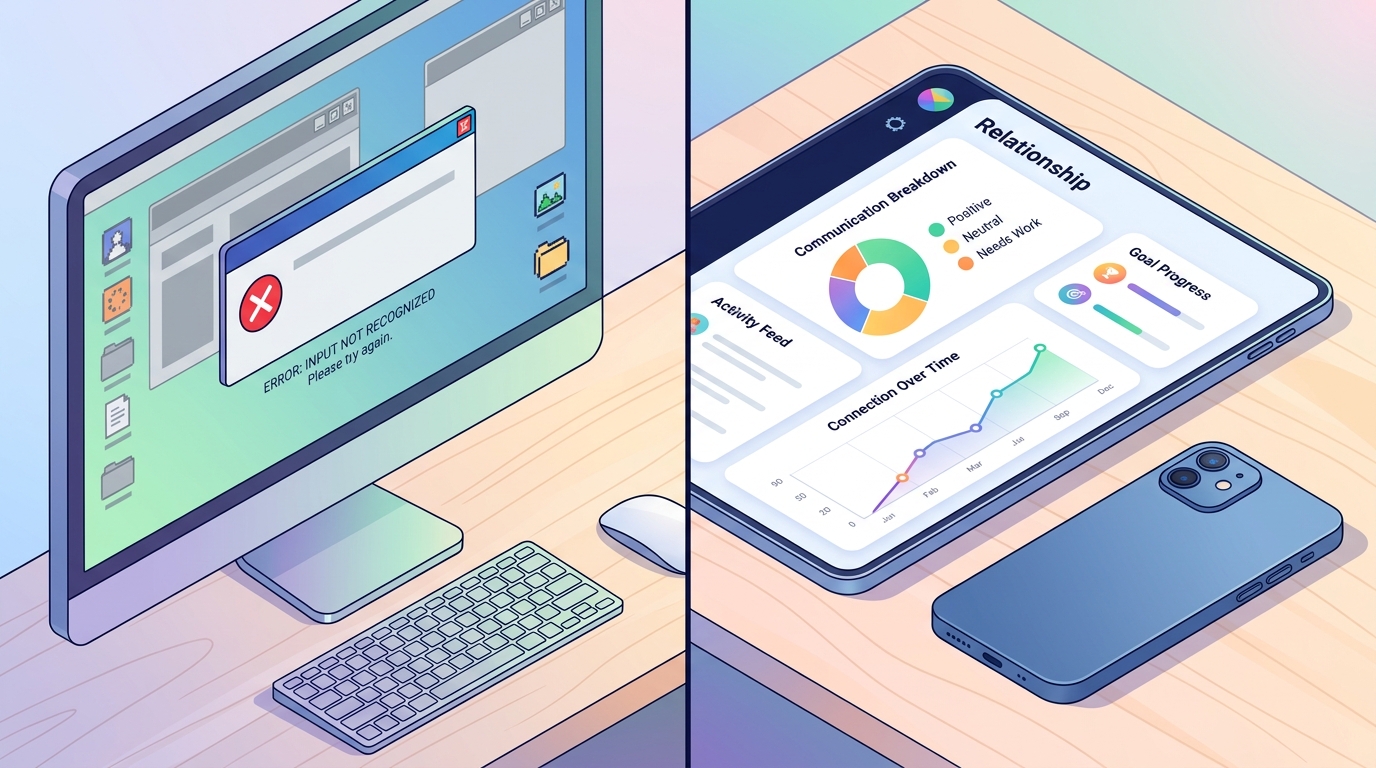
Benadering B: De gespecialiseerde pipeline
Contrastteer dit met een speciaal ontwikkelde analyse-app. Door de AI specifiek te integreren voor de structuur van messenger-logs, verdwijnt de frictie.
- Native parsing: De tool herkent automatisch tijdstempels, afzenders en de standaard opmaak van berichtendiensten.
- Diepe segmentatie: In plaats van tegen token-limieten aan te lopen, deelt de backend de data logisch op (bijv. per maand of per belangrijke gebeurtenis) terwijl de rode draad van de context behouden blijft.
- Verhalende output: Het eindresultaat is niet slechts een lijst met bullets, maar een gestructureerde tijdlijn, een highlight-reel of een relatieprofiel.
Bij het analyseren van wereldwijd zoekgedrag zien we fascinerende lokale intenties die deze vraag naar specialisatie onderstrepen. Turkse gebruikers zoeken bijvoorbeeld vaak naar een specifieke workflow: een uygulama (app) waar ze hun whatsapp sohbet (chat) logs kunnen yükleyerek (uploaden) om uit hun geçmişini (geschiedenis) direct eğlenceli (leuke) özetler (samenvattingen) te genereren. Ze zoeken actief naar nauwkeurige analizler (analyses) en hebben een systeem nodig dat het contextuele werk veilig voor hen doet (yapan), wetende dat een toegewijde app (uygulamadır) beter presteert dan een lege prompt.
Privacy, vertrouwen en opt-in-gedrag
Een andere belangrijke factor die gebruikers wegdrijft van algemene webinterfaces naar gespecialiseerde apps, is de controle over data. Het uploaden van jaren aan persoonlijke geschiedenis naar een brede ai-trainingspool geeft veel gebruikers een ongemakkelijk gevoel. Toegewijde apps die data lokaal verwerken of direct na analyse verwijderen, bieden een duidelijkere privacybelofte.
Het Adjust-rapport van 2026 levert hard bewijs dat gebruikers bereid zijn apps te vertrouwen wanneer deze belofte duidelijk is. De data laat zien dat de opt-in-percentages voor iOS App Tracking Transparency (ATT) zijn gestegen van 35% in Q1 2025 naar 38% in Q1 2026. Deze opwaartse trend suggereert dat wanneer gebruikers de waarde begrijpen — en het platform vertrouwen — ze steeds vaker bereid zijn noodzakelijke machtigingen te delen. Mensen zijn niet per definitie tegen dataverwerking; ze zijn tegen ondoorzichtige dataverwerking.
Dit sluit nauw aan bij wat Naz Ertürk besprak over AI-chatgewoonten, waarbij zij opmerkte dat gebruikers de voorkeur geven aan omgevingen waar de grenzen van datagebruik expliciet zijn gedefinieerd. Of ze nu wegstappen van ongeautoriseerde aangepaste clients (vaak gezocht met termen als gb whatsapp download) of officiële tools zoals een whatsapp business download, de prioriteit blijft strikte controle over de geëxporteerde tekst.
Waarom context belangrijker is dan brute rekenkracht
Het is makkelijk om aan te nemen dat de meest bekende modellen — zoals chats gpt, chàt gpt of de standaard chat gpt varianten — inherent overal de beste in zijn. Ze beschikken over enorme parameters en brede kennis. Maar persoonlijke berichten draaien niet om brede kennis; het gaat om hyper-lokale, diepe context.
Je chatgeschiedenis is een intieme dataset met een eigen vocabulaire, tempo en emotionele cadans. Een generiek chat-model benadert deze data als een tekstboek en extraheert droge feiten. Een speciaal gebouwde app benadert de data als een biograaf, op zoek naar gedragspatronen, de meest actieve uren, veelgebruikte emoji's en communicatiestijlen. Zoals Naz Ertürk opmerkte in haar vergelijking tussen algemene tools en recap-apps, hangt de beste optie volledig af van de vraag of je een snel feitelijk antwoord wilt of een diep gepersonaliseerd verhaal.

De toekomst van persoonlijke data-analyse
Het bereiken van 100.000 verwerkte exports heeft onze aanpak bij Dynapps LTD fundamenteel bevestigd. Het tijdperk waarin gebruikers zelf complexe prompts moeten uitvogelen om waarde uit hun eigen data te halen, loopt ten einde.
Wanneer iemand probeert een enorm bestand samen te vatten met cha t gpt of chatgtp, gebruiken ze in feite een Zwitsers zakmes om een huis te bouwen. Het werkt wel, maar het is uiterst inefficiënt en frustrerend. De mobiele app-economie verschuift naar geïntegreerde oplossingen die de technische complexiteit achter de schermen afhandelen en de gebruiker alleen voorzien van gepolijste, definitieve inzichten. Voor persoonlijke relatie-analyse en exportsamenvattingen hebben gespecialiseerde tools de standaardverwachting definitief veranderd.