
Imaginez que vous exportiez une conversation massive de cinq ans avec votre meilleur ami, en espérant qu'un outil de chat par intelligence artificielle transforme instantanément ces fichiers texte bruts en un récit cohérent. Vous collez le journal dans une zone de saisie standard, pour ne recevoir qu'un résumé générique, truffé d'hallucinations, qui passe totalement à côté des blagues privées et du contexte chronologique. Cette analyse majeure compare les performances des modèles génériques face aux applications de résumé spécialisées, révélant que les utilisateurs abandonnent massivement le « prompt engineering » manuel au profit d'architectures intégrées et conçues sur mesure. Alors que nous franchissons le cap des 100 000 exports de chat traités, les données confirment un changement structurel : les gens veulent des systèmes qui analysent nativement leur histoire personnelle, plutôt que d'être forcés de jouer les ingénieurs de requêtes.
La fin de la phase de « hype » des chatbots
Ces dernières années, le comportement standard des utilisateurs pour l'analyse de texte consistait à copier des données et à les coller dans n'importe quelle interface générale disponible. Qu'ils tapent chatgpt, essaient gemini ou expérimentent de nouveaux modèles comme deepseek et grok ai, l'attente était qu'un modèle suffisamment avancé puisse déchiffrer n'importe quel amas de données brouillonnes. Cependant, les données réelles de rétention racontent une tout autre histoire.
Selon le rapport Mobil Uygulama Trendleri 2026 publié par Adjust, la phase initiale de « hype de l'IA » est officiellement terminée. Le rapport souligne que les dépenses mondiales des consommateurs en applications ont augmenté de 10,6 % pour atteindre 167 milliards de dollars en 2025, avec une hausse de 7 % des sessions globales. Surtout, les chercheurs notent que la croissance en 2026 dépend fortement de la discipline opérationnelle — spécifiquement l'intégration de bout en bout de l'IA pour la segmentation et l'optimisation, plutôt que de s'appuyer sur des outils fragmentés. Les utilisateurs ne veulent plus d'un outil déconnecté où ils doivent faire tout le travail ; ils attendent que l'application gère l'intégralité du flux de travail nativement.
Dans mon expérience de conception de services basés sur la localisation et d'applications de suivi familial, j'ai observé exactement ce changement de comportement. Lorsque les utilisateurs manipulent des données profondément personnelles — qu'il s'agisse de coordonnées de localisation ou de messages privés — ils préfèrent largement les environnements spécialisés en circuit fermé plutôt que de coller leur vie dans une interface web publique. Ils veulent une expérience sur mesure qui respecte le format de leurs données.
Comparaison des deux approches : Bricolage vs Solution dédiée
Pour comprendre pourquoi ce changement se produit, nous devons comparer l'approche manuelle consistant à utiliser un chatbot ia standard face à un flux de travail dédié comme Wrapped AI Chat Analysis Recap. Si vous voulez un récit structuré de la dynamique de votre relation, le moteur de traitement de Wrapped AI est conçu pour ce résultat spécifique, évitant les erreurs courantes des modèles généraux.
Approche A : Le prompt d'IA générique
Lorsqu'un utilisateur tente de traiter un fichier volumineux via un gpt chat standard ou une interface web similaire, il se heurte immédiatement à des frictions. Les journaux de messages exportés de plateformes comme whatsapp web ou whatsapp messenger contiennent des horodatages, des messages système et des indicateurs de médias qui déroutent les modèles de langage généraux.
- Limites de tokens : La plupart des modèles standards limitent la quantité de texte que vous pouvez saisir. Une année de messages quotidiens dépasse facilement ces limites, forçant l'utilisateur à découper manuellement son texte.
- Fragmentation du contexte : Parce que le texte est découpé, le modèle perd la chronologie globale. Il peut penser qu'une dispute résolue en mars est toujours en cours en décembre.
- Hallucinations : Face à des données désordonnées, les outils généraux inventent fréquemment du contexte ou fusionnent deux personnes différentes en une seule personnalité.
Nous voyons des utilisateurs chercher constamment des solutions de contournement, tapant des requêtes comme wchat gpt, chat gp t, ou même des variantes mal orthographiées comme char gbt et gbt char, espérant trouver un modèle de prompt spécifique qui corrigera leur résultat médiocre. Mais le défaut n'est pas le prompt ; c'est l'architecture.
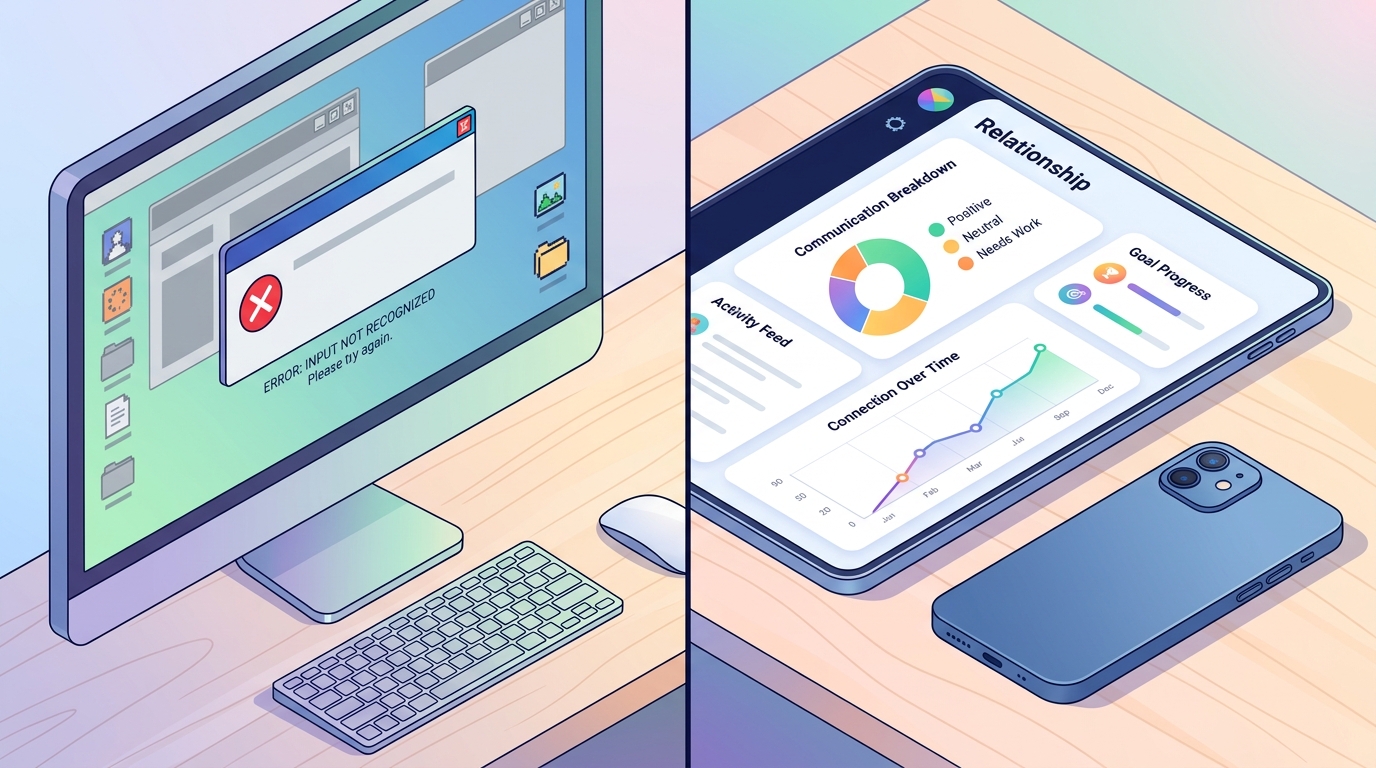
Approche B : Le pipeline spécialisé
Comparez cela avec une application d'analyse dédiée. En intégrant l'IA spécifiquement pour les structures de journaux de messagerie, la friction disparaît.
- Analyse native : L'outil reconnaît automatiquement les horodatages, les noms des locuteurs et le formatage standard des messageries.
- Segmentation profonde : Au lieu de buter sur les limites de tokens, le backend fragmente les données logiquement (par exemple, par mois ou par événement majeur) tout en maintenant un fil contextuel global.
- Rendu narratif : Le résultat final n'est pas une simple liste de puces, mais une chronologie structurée, un florilège des moments forts ou un profil relationnel.
En analysant les comportements de recherche mondiaux, nous remarquons des intentions locales fascinantes qui soulignent cette demande de spécialisation. Par exemple, les utilisateurs cherchent activement des outils précis pour transformer leurs historiques whatsapp en résumés amusants. Ils ont besoin d'un système capable de réaliser le travail contextuel de manière sécurisée, reconnaissant qu'une application dédiée surpasse un prompt vide.
Confidentialité, confiance et consentement
Un autre facteur majeur éloignant les utilisateurs des interfaces web génériques vers des applications spécialisées est le contrôle des données. Télécharger des années d'histoire personnelle vers un pool d'entraînement d'IA général met de nombreux utilisateurs mal à l'aise. Les applications dédiées qui traitent les données localement ou les suppriment immédiatement après l'analyse offrent un contrat de confidentialité beaucoup plus clair.
Le rapport Adjust 2026 prouve que les utilisateurs sont prêts à faire confiance aux applications lorsque ce contrat est explicite. Les données montrent que les taux de consentement à l'App Tracking Transparency (ATT) sur iOS sont passés de 35 % au T1 2025 à 38 % au T1 2026. Cette tendance suggère que lorsque les utilisateurs comprennent l'échange de valeur — et font confiance à la plateforme — ils sont de plus en plus à l'aise pour partager les autorisations nécessaires. Les gens ne sont pas intrinsèquement opposés au traitement des données ; ils sont opposés au traitement opaque des données.
Cela rejoint étroitement ce que Naz Ertürk a discuté concernant les habitudes de chat par intelligence artificielle, notant que les utilisateurs préfèrent fortement les environnements où les limites d'utilisation des données sont explicitement définies. Qu'ils s'éloignent de clients modifiés non autorisés (souvent recherchés via gb whatsapp download) ou d'outils officiels comme whatsapp business, la priorité reste un contrôle strict sur le texte exporté.
Pourquoi le contexte importe plus que la puissance brute
Il est facile de supposer que les modèles les plus célèbres — comme chats gpt, chàt gpt, ou les variantes standards de chat gpt — sont intrinsèquement les meilleurs pour tout. Ils possèdent des paramètres massifs et des connaissances étendues. Mais la messagerie personnelle ne relève pas de la connaissance étendue ; elle relève du contexte profond et hyper-local.
Votre historique de chat est un ensemble de données intimes. Il possède son propre vocabulaire, son rythme et sa cadence émotionnelle. Un modèle de chat générique aborde ces données comme un manuel scolaire, en extrayant des faits froids. Une application spécialisée aborde les données comme un biographe, cherchant les schémas comportementaux, les heures les plus actives, les emojis fréquents et les styles de communication. Comme Naz Ertürk l'a souligné dans sa comparaison entre outils génériques et applications de récapitulatif, la meilleure option dépend entièrement de si vous voulez une réponse factuelle rapide ou un récit profondément personnalisé.

L'avenir de l'analyse des données personnelles
Atteindre 100 000 exports traités a fondamentalement validé notre approche chez Dynapps LTD. L'ère consistant à forcer les utilisateurs à concevoir des prompts complexes pour extraire de la valeur de leurs propres données touche à sa fin.
Quand quelqu'un tente de résumer un fichier massif en utilisant cha t gpt ou chatgtp, il utilise essentiellement un couteau suisse pour construire une maison. Cela fonctionne, mais c'est inefficace et frustrant. L'économie des applications mobiles évolue vers des solutions intégrées qui gèrent la complexité technique en coulisses, ne présentant à l'utilisateur que l'analyse finale et raffinée. Pour l'analyse des relations personnelles et les résumés d'exports, les outils spécialisés ont définitivement changé la donne.