
親友との5年間にわたる膨大な会話履歴をエクスポートし、AIツールがその生のテキストデータを意味のある物語に即座に変えてくれることを期待したとしましょう。しかし、標準的なプロンプトボックスにログを貼り付けても、返ってくるのは、内輪ネタや時系列の文脈を完全に見落とした、汎用的で「もっともらしい嘘(ハルシネーション)」の要約であるケースがほとんどです。今回の分析では、汎用モデルと特化型の要約アプリの性能を比較し、ユーザーが手動のプロンプトエンジニアリングを離れ、専用に構築された統合アーキテクチャへと急速に移行している現状を浮き彫りにします。10万件を超えるチャットエクスポートの処理という節目を迎え、データはある構造的な変化を裏付けました。人々は、自分自身がプロンプトエンジニアになるのではなく、個人の履歴をネイティブに解析してくれるシステムを求めているのです。
チャットボット・ハイプサイクルの終焉
ここ数年、テキスト分析における標準的なユーザー行動は、データをコピーして利用可能な汎用インターフェースに貼り付けることでした。ChatGPTやGemini、あるいはDeepSeekやGrok AIのような新しいモデルを試すにせよ、期待されていたのは「十分に高度なモデルであれば、どんなに乱雑なデータダンプでも理解できるはずだ」ということでした。しかし、実際のユーザー維持データは異なる物語を語っています。
Adjustが発表したレポート『モバイルアプリトレンド 2026』によると、初期の「AIブーム」段階は公式に終了しました。同レポートは、2025年の世界の消費者アプリ支出が10.6%増の1,670億ドルに達し、アプリセッション全体が7%増加したことを強調しています。重要なのは、2026年の成長は「運用の規律」、具体的には、断片的なスタンドアロンツールに頼るのではなく、セグメンテーション、洞察、最適化のためにAIをエンドツーエンドで統合できるかどうかにかかっていると研究者が指摘している点です。ユーザーはもはや、自分で重労働(プロンプトの調整など)をしなければならない切り離されたツールを望んでおらず、アプリケーションがワークフロー全体をネイティブに管理することを期待しています。
位置情報サービスや家族追跡アプリの設計に携わってきた私の経験からも、この行動の変化を実感しています。ユーザーが位置座標やプライベートなメッセージといった極めて個人的なデータを扱う際、彼らは公開ウェブインターフェースに自分の人生を貼り付けるよりも、クローズドで特化した環境を強く好みます。データの形式を尊重した、カスタマイズされた体験を求めているのです。
2つのアプローチの比較:DIYか、専用設計か
なぜこのシフトが起きているのかを理解するために、標準的な「AIチャットボット」を使用する手動アプローチと、Wrapped AI(チャット解析リキャップ)のような専用のワークフローを比較してみましょう。もし人間関係の力学を構造化された物語として知りたい場合、Wrapped AIの処理エンジンは、汎用モデルでよくあるエラーを回避し、その特定の結果を得るために設計されています。
アプローチA:汎用AIプロンプト
ユーザーが標準的なGPTチャットや同様のウェブインターフェースを使用して大きなファイルを処理しようとすると、すぐに摩擦が生じます。WhatsApp WebやWhatsApp Messengerからエクスポートされたメッセージログには、タイムスタンプ、システムメッセージ、メディアのプレースホルダーが含まれており、これらが汎用言語モデルを混乱させます。
- トークン制限: ほとんどの標準モデルには入力できるテキスト量に上限があります。1年分の日々のメッセージは簡単にこの制限を超え、ユーザーは手動でテキストを分割(スライス)せざるを得ません。
- コンテキストの断片化: テキストが分割されるため、モデルは全体のタイムラインを見失います。3月に解決したはずの喧嘩が12月にも続いていると誤認することもあります。
- ハルシネーション: 乱雑なデータに直面すると、汎用ツールはしばしば文脈を捏造したり、2人の別人を1人の人格に統合したりします。
ユーザーは、wchat gpt、chat gp t、さらにはchar gbtやgbt charといった誤字を含んだ検索を繰り返し、乱雑な出力を修正できる特定のプロンプトテンプレートを探し求めています。しかし、欠陥があるのはプロンプトではなく、アーキテクチャそのものなのです。
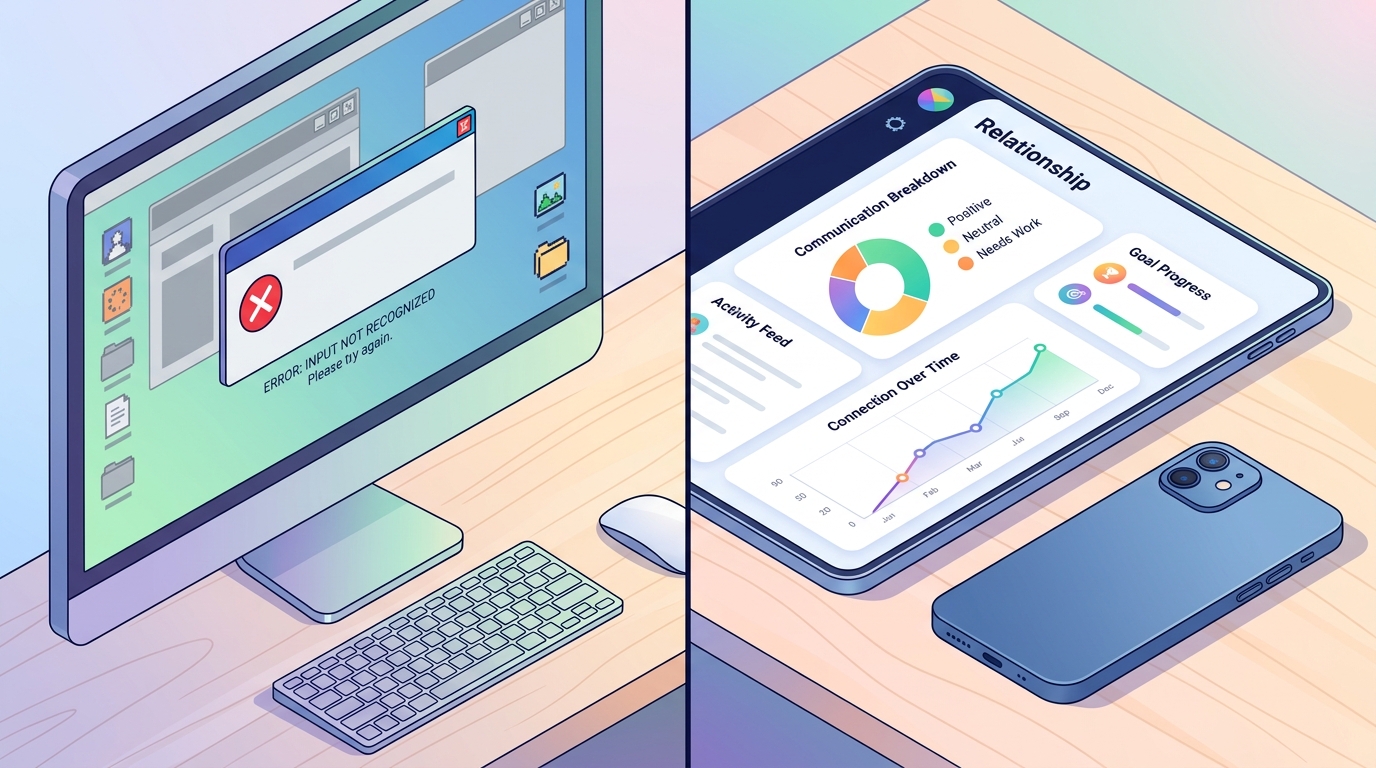
アプローチB:特化型パイプライン
これとは対照的に、専用の分析アプリはどうでしょうか。メッセンジャーログの構造に合わせてAIを特別に統合することで、摩擦は消失します。
- ネイティブ解析: ツールがタイムスタンプ、話者ラベル、メッセンジャーの標準フォーマットを自動的に認識します。
- 深いセグメンテーション: トークン制限にぶつかる代わりに、バックエンドがグローバルなコンテキストを維持しながら、データを論理的(月別や主要イベント別など)に分割処理します。
- 物語形式の出力: 最終結果は単なる箇条書きのリストではなく、構造化されたタイムライン、ハイライトリール、または関係性プロフィールとして提示されます。
世界の検索行動を分析すると、この特化への需要を浮き彫りにする興味深いローカライズされた意図が見て取れます。例えばトルコのユーザーは、「uygulama(アプリ)」を使って「whatsapp sohbet(チャット)」ログを「yükleyerek(アップロード)」し、自分の「geçmişini(履歴)」から即座に「eğlenceli(楽しい)」「özetler(要約)」を生成するという特定のワークフローを頻繁に検索しています。彼らは、汎用的なプロンプトよりも専用アプリ(uygulamadır)の方が優れていることを認識し、安全かつ文脈に沿った作業を「yapan(実行する)」、正確な「analizler(分析)」を積極的に求めているのです。
プライバシー、信頼、そしてオプトイン行動
ユーザーが汎用的なウェブインターフェースを避け、専用アプリを選ぶもう一つの大きな要因はデータコントロールです。何年分もの個人的な履歴を広範なAI学習プールにアップロードすることに抵抗を感じるユーザーは少なくありません。データをローカルで処理するか、分析後すぐに削除する専用アプリは、より明確なプライバシー契約を提供します。
Adjustの2026年レポートは、この契約が明確であれば、ユーザーはアプリを信頼する用意があるという強力な証拠を示しています。データによると、iOSの「アプリのトラッキングの透明性(ATT)」のオプトイン率は、2025年第1四半期の35%から2026年第1四半期には38%に上昇しました。この上昇傾向は、ユーザーが価値の交換を理解し、プラットフォームを信頼すれば、必要な許可を共有することに抵抗がなくなっていることを示唆しています。人々はデータ処理そのものに反対しているのではなく、不透明なデータ処理に反対しているのです。
これは、Naz ErtürkがAIチャットの習慣について議論した内容とも一致しており、ユーザーはデータの使用境界が明示的に定義されている環境を強く好むと述べています。非公式の改造クライアント(gb whatsapp downloadなどで検索される)から離れるにせよ、公式のwhatsapp business downloadを使用するにせよ、優先事項はエクスポートされたテキストの厳格な管理にあります。
パワーよりもコンテキストが重要な理由
ChatGPT(あるいはchats gpt、chàt gptなどの表記揺れ)のような最も有名なモデルが、あらゆる面で本質的に優れていると想定しがちです。それらは膨大なパラメータと広範な知識を持っています。しかし、個人のメッセージングに必要なのは広範な知識ではなく、極めてローカルで深い「文脈(コンテキスト)」です。
あなたのチャット履歴は親密なデータセットです。そこには独自の語彙、ペース、感情のリズムがあります。汎用的なチャットモデルはこのデータを教科書のように扱い、無機質な事実を抽出します。一方、専用設計のアプリはバイオグラファー(伝記作家)のようにデータを扱い、行動パターン、最も活動的な時間帯、頻繁に使う絵文字、コミュニケーションスタイルを探し出します。Naz Ertürkが汎用ツールとリキャップアプリを比較した際に指摘したように、最良の選択肢は、単なる事実の回答が欲しいのか、それとも深くパーソナライズされた物語が欲しいのかによって決まります。

個人データ分析の未来
10万件のエクスポート処理という実績は、Dynapps LTDにおける私たちの開発アプローチが正しかったことを根本から証明しています。ユーザーに自分のデータから価値を引き出すために複雑なプロンプトを考えさせる時代は終わりつつあります。
cha t gptやchatgtpを使って巨大なファイルを要約しようとするのは、いわばスイスアーミーナイフだけで家を建てようとするようなものです。不可能ではありませんが、非常に非効率でストレスが溜まります。モバイルアプリ経済は、技術的な複雑さを裏側で処理し、ユーザーには磨き上げられた最終的な洞察のみを提供する統合ソリューションへと移行しています。個人の人間関係分析やエクスポートの要約において、特化型ツールは期待される基準を恒久的に変えたのです。